










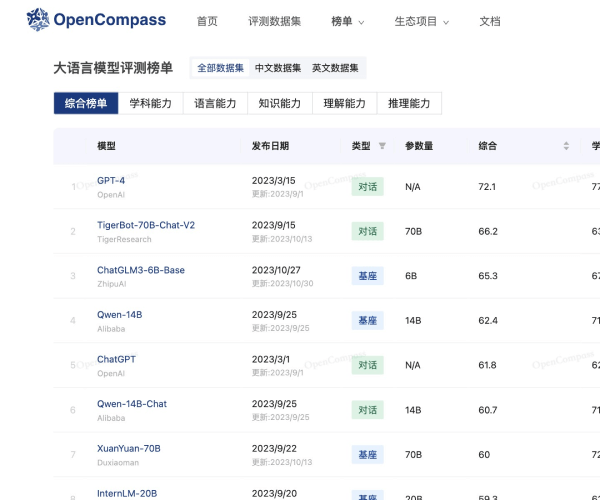
OpenCompass是上海人工智能实验室开源的大模型评测平台,涵盖学科、语言、知识、理解、推理等五大评测维度,支持50余个数据集的评测,Qwen、LLaMA2等开源模型及GPT-4、ChatGPT等主流模型均参与评测,可全面评估大模型能力,是业界公认最权威的中文能力评测榜单之一。

其特点包括开源可复现、全面的能力维度、丰富的模型支持、分布式高效评测、多样化评测范式以及灵活化拓展。OpenCompass构建了一套高质量的中英文双语评测基准,涵盖语言与理解、常识与逻辑推理、数学计算与应用、多编程语言代码能力、智能体、创作与对话等多个方面,能够实现对大模型真实能力的全面诊断。
OpenCompass的工具架构包括配置、推理、评估、可视化等步骤,评测方法分为客观和主观两种,客观评测又包括判别式评测(困惑度)和生成式评测(生成类任务)。同时,OpenCompass推出了大模型评测全栈工具链CompassKit,包括OpenCompass升级版大语言模型评测工具、VLMEvalKit多模态大模型评测工具、Code-Evaluator代码评测服务工具以及MixtralKit MoE模型入门工具等。
此外,OpenCompass还包括CompassRank和CompassHub两个子平台。CompassRank作为OpenCompass中各类榜单的承载平台,保持中立性,并依托CompassKit工具链体系中的各类评测手段,保证了榜单的客观性。CompassHub则是面向大模型能力评测开源开放的基准社区,提供面向不同能力维度和行业场景的评测基准。
总之,OpenCompass是一个全面、开放、可复现的大模型评测体系,为大模型的评估和优化提供了有力的支持。
@版权声明:部分内容从网络收集整理,如有侵权,请联系删除!
类似网站









AI569工具箱收录了国内外当下流行的数百款 ai工具,定期检查更新最新的好用工具,工具包含了ai文本模型、ai绘画模型、ai 视频模型、ai声音模型等各种类型!Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
Copyright © AI569工具导航站-ai工具大全
京ICP备16027678号-17
 川公网安备 123456789号
川公网安备 123456789号