










在人工智能领域,对语言模型性能的评估一直是研究的热点。大规模多任务语言理解(Massive Multi-task Language Understanding, 简称MMLU)正是一项引领这一潮流的综合评估方法。它侧重于在零样本和少样本设置下,衡量文本模型在多个任务上的准确性,从而全面评估其多任务处理能力。
MMLU不仅涵盖了基础数学、美国历史、计算机科学和法律等经典领域,更是扩展到了总计57项任务。这些任务要求模型展现出广泛的知识基础和卓越的问题解决能力,以应对来自不同领域的挑战。
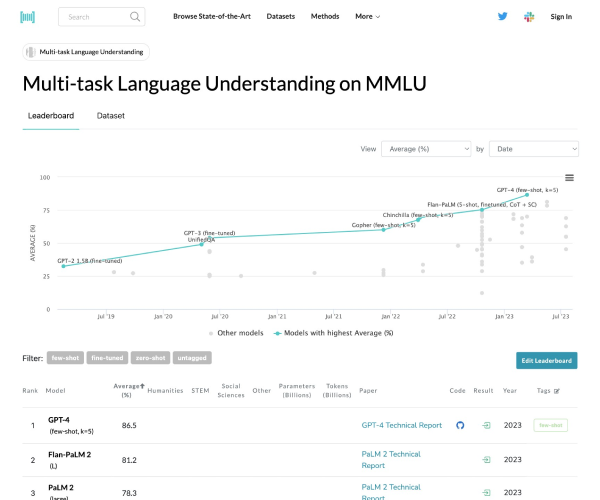
MMLU为研究者们提供了一个理想的平台,用于测试和比较各种语言模型,如OpenAI GPT-4、Mistral 7b、Google Gemini和Anthropic Claude 2等。通过这一基准测试,我们可以更准确地了解这些模型在不同任务上的表现,从而为其优化和应用提供有力支持。

广泛的科目覆盖:MMLU基准测试涵盖了从基础数学到法律和道德等高级专业水平的57个科目,确保了评估的全面性和深度。
卓越的粒度和广度:该测试不仅考察模型的世界知识,还着重评估其解决问题的能力,使其成为衡量模型对各类主题理解程度的理想选择。
多任务准确性的全面评估:MMLU通过多样化的任务设置,全面评估模型的多任务准确性,确保对模型的学术和专业知识进行全方位、多角度的考量。
无需大型训练集:与其他基准测试不同,MMLU假设模型已经通过预训练获得了必要的知识。这种设计不仅提高了测试效率,还使得模型在真实世界中的应用更加灵活和便捷。
定量比较不同模型:MMLU为研究者们提供了一个量化的标准,使得不同语言模型之间的性能比较更加客观和准确。
高效且易于理解:该测试设计合理、操作简便,使得评估过程既高效又易于理解,为研究者们节省了大量时间和精力。
全面捕捉语言结构:MMLU不仅关注模型在特定任务上的表现,还考虑其在各种语境中理解和生成语言的能力,从而更全面地捕捉语言结构的某些方面。这些优势使得MMLU成为评估语言模型性能及其在各种语境中理解和生成语言能力的宝贵工具。









 川公网安备 123456789号
川公网安备 123456789号